

Teaching AI to play games
Perhaps the most striking example of the complexity and nuances of creating a virtual gaming agent is Google’s DeepMind project. The virtual AlphaGo player that emerged from this project beat the strongest Go player in history and made a move that was considered impossible at the time. Note, Go is a strategic two-player board game invented in China; the aim of the players is to take more territory than their opponent.
When it comes to creating artificial agents for gaming, having them outsmart players may be a strategy for disaster in a certain digital world. There is a need to keep them as smart as necessary to provide fun and engagement to players of various skill levels. Having AI achieve human-level skill can lead to frustration and players simply quitting games en mass.
The best example of AI achieving human-level skill in a multiplayer shooter was research undertaken on the popular game Quake III Arena. Using reinforcement learning (RL), the AI managed to make complex decisions and beat out its human competition in some instances. But what is reinforcement learning, and why is it used in gaming and simulations? Let’s find out.
Deep Reinforcement Learning
Deep reinforcement learning (DRL) has made great strides since being initially proposed. It consists of RL and deep learning. While RL leads an AI agent to make decisions by trial and error, DRL allows it to make decisions based on unstructured input without the need for any manual engineering during the performance of the activities.
Meanwhile, in gaming, such machine learning is used to generate automated behavior by in-game NPCs (non-player characters). And while we touched on using complex AI in games, DRL and RL have their use in serious games. A serious game (SG) is a term that refers to games not exclusively built for entertainment but for creating educational value. While SGs are often times built for a specific audience, an industrial branch, or a company, they have the potential to take over the world of e-learning.
Another important part of the DRL and RL story and what it created today is Simulation. Let’s look at a simulation and why it’s important.

Markov model of deep learning. Source: VMWare
Simulation of deep reinforcement learning
Let’s start by defining the term simulation, as it can mean numerous things. Simulations can range from flight simulators to simulations of electrical and mechanical components. A good starting definition is given by TWI, a research and technology organization:
“A simulation imitates the operation of real-world processes or systems with the use of models.”
In essence, a system that has numerous inputs applies mathematical functions to the inputs and delivers an output in the form of data would be the most simple definition of a simulation. They’re important for our discussion as deep reinforcement learning requires a high number of trial-and-error sequences in order to learn. These trial and error sequences are often done as an interaction with an environment, and simulation and simulators provide this in the most cost-effective and timely manner.
Google’s Alpha Go played its thousands of matches in a simulation, allowing them to take place in the digital realm instead of playing against real players, which would raise the cost to the point of it not being commercially viable to develop these AI models.
That being said, simulations have great value in industrial applications, and a great example of this is Microsoft’s Bonsai project. This AI platform allows enterprises to program controls in industrial systems using DRL. The firms can build a “BRAIN” (AI model), connect a simulator, and train the desired behavior for industrial applications.
Moreover, besides gaming and automating mundane tasks, DRL and RL potentially have a much greater use case. Have you heard of Chat GPT? We have, and we bet you have too. An AI chatbot that is taking the world by storm, but how does it work? Let’s see!
How Chat GPT works
Chat GPT is a “continuation,” or some might call it a spinoff of Instruct GPT, which introduced an approach of incorporating human feedback into the training data set. RL from human feedback helped create the amazing things that Chat GPT is currently displaying; however, it is not the only building block behind the chatbot that took the world by storm. Over 40 contractors collected actual queries by humans into the Open API platform and then wrote responses to each query.
When it was all said and done, the supervised dataset used to train the chatbot contained 13,000 input and output samples. After that, the team created a reward model, a series of prompts and responses, and the output is a scalar value or a reward. And in the final stage, the model generates output based on the policy that the model learned to maximize its reward. The rewards are fed back into the system to evolve the policy and create better output for users’ queries.
Obviously, the model is much more complex and nuanced than what was described in the simplified version above, and for those wishing to get into more technical details, the original paper is the best source of information.
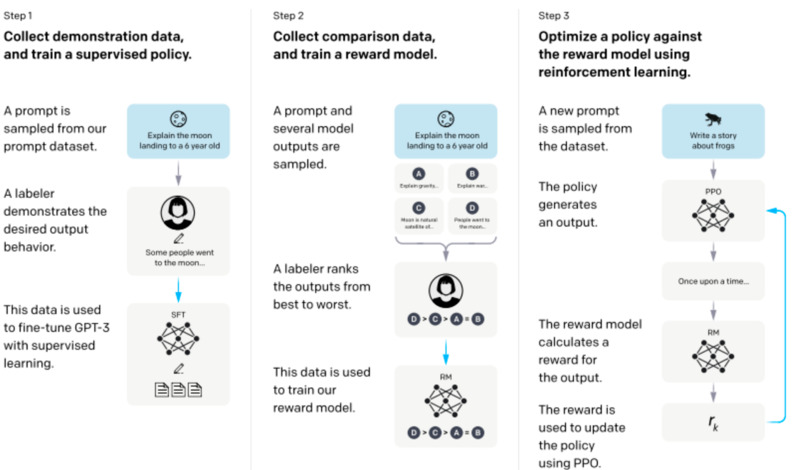
Training language model from OpenAI. Source: Arxiv
The future of our AI superhero
At the moment, experts in the field are looking into multi-environment training and the use of language modeling to help AI learn across multiple domains. This statement often leads to philosophical discussions on artificial general intelligence (AGI), a type of AI that can learn any intellectual task that a human being can. This vision of the future predicts super-smart machines working alongside humans to solve almost any issue that humanity may face. Disease, climate issues, energy, economics, physics, etc.
While this meta-solution may be deceased off into the future or may actually never pan out as envisioned by futurists, the fact is that we’re inching closer to it. The amazing results shown by Chat GPT, thanks to the combination of RL and deep neural networks, gave us a test of the potential future we may be facing. While information overload may be an issue now, having something akin to Chat GPT may, in fact, lead us to neglect our intellectual capacities in the long run.
Regardless, RL and DRL have created a movement that will probably be difficult to stop, and we should enjoy the developments and amazing future that is ahead of us.









